🗨 개인적인 공부 기록용으로 정리한 내용입니다. 잘못된 내용에 대한 피드백은 언제나 감사합니다 :)
⭐리스트는 동적 크기를 가지며 순차적으로 데이터를 저장하는 자료구조이다.
📌 리스트의 정의
리스트는 선형 자료구조의 한 종류이며, 배열과 유사하게 데이터를 연속적으로 저장하는 자료구조이다.
리스트는 구체적인 형태에 따라 배열 리스트(Array List)나 연결 리스트(Linked List)로 나뉜다.
배열 리스트(Array List)는 배열을 기반으로 구현된 리스트고, 연결 리스트(Linked List)는 각 요소가 다른 요소에 대한 참조(포인터)를 가지며, 동적으로 크기를 조절할 수 있는 리스트다.
📌 1) 배열 리스트(Array List)
동적 배열(Dynamic Array)이라 불리기도 한다.
배열 기반으로 구현되므로, 데이터가 연속된 메모리 공간에 저장된다.
그리고 크기가 고정되지 않는 게 특징이다.
많은 프로그래밍 언어에서는 리스트(List)라는 자료형을 제공하며, 이는 메모리 내부적으로, 동적으로 크기가 조절되는 배열의 형태로 구현된다. C++의 `std::vector` 또는 C#의 `List<T>`가 이에 해당한다.
🔖 배열 리스트의 장점
- 연속적으로 저장되기 때문에, 인덱스를 통해 각 요소에 임의 접근(random access)을 할 수 있어 접근 속도가 매우 빠르다.
- ⏱ 시간 복잡도는 $\mathbf{O(1)}$이다.
- 데이터가 추가되면 자동으로 배열의 크기가 증가하므로 유연하게 사용할 수 있다.
- 연속적인 공간을 사용하므로 메모리를 효율적으로 사용할 수 있다. (캐시 효율성이 좋다.)
🔖 배열 리스트의 단점
- 배열 기반이므로 삽입 및 삭제가 비효율적이다.
- 중간에 데이터를 삽입하거나 삭제할 때 데이터를 옮겨야 하므로, ⏱ 시간 복잡도가 $\mathbf{O(n)}$이다.
- 재할당 비용이 필요하기 때문에 크기를 자주 확장해야 하는 경우엔 연결 리스트가 더 적합할 수 있다.
- 배열의 크기를 늘려야 하는 상황일 때, Array Doubling이 발생하는데, 이때 성능이 일시적으로 저하된다.
- Array Doubling : 기존 크기의 두 배에 해당되는 배열을 선언하고, 모든 요소들을 새로 할당받은 배열로 옮기는 작업.
- 배열 크기를 미리 두 배로 할당하기 때문에 사용되지 않는 메모리 공간은 낭비될 수 있다.
🔖 배열 리스트의 사용
- 크기가 고정되지 않으므로 동적인 데이터 저장이 필요할 때 사용된다.
- 삽입 및 삭제 작업은 적고, 배열에 저장된 데이터를 검색하는 작업이 많을 때 사용하기 좋다.
- 사용자가 입력한 데이터를 실시간으로 받아 저장해야 할 때, 배열 리스트를 사용하면 미리 크기를 알지 못해도 동적으로 데이터 크기를 조절할 수 있다.
📌 2) 연결 리스트(Linked List)
연결 리스트는 배열의 특징을 가진 배열 리스트의 문제점(삭제 및 삽입시 데이터 이동)을 보완한 방법이다.
연결 리스트는 데이터의 요소들이 메모리 상에서 연속적으로 저장되지 않고, 각 요소가 다음 요소를 가리키는 포인터를 통해 연결된 형태를 가진다.
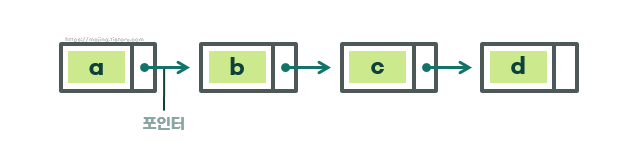
줄로 연결된 상자처럼 생겼다.
연결 리스트는 `노드(Node)`라는 단위로 구성되며, 각 노드는 `데이터(Data)`와 `포인터(Next)`로 구성된다.
- `데이터(Data)` : 노드가 저장하는 값.
- `포인터(Pointer)` : 다음 노드를 가리키는 참조(포인터)
🔖 연결 리스트의 종류
- 단일 연결 리스트 (Singly Linked List) : 한 방향으로만 연결된 리스트

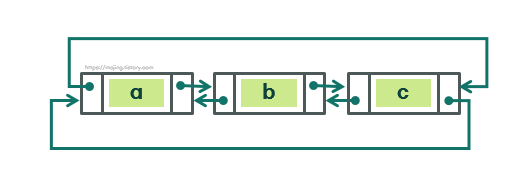
단일 연결 리스트 - 이중 연결 리스트 (Doubly Linked List) : 각 노드가 이전 노드와 다음 노드를 가리키는 두 개의 포인터를 가지는 리스트

이중 연결 리스트 - 원형 연결 리스트 (Circular Linked List) : 마지막 노드가 첫 번째 노드를 가리키는 형태로 연결된 리스트
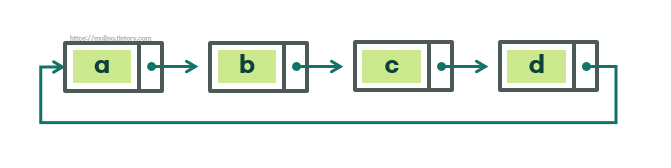
실제로는 이중 연결 리스트와 원형 연결 리스트를 혼합시킨 형태인 원형 이중 연결 리스트(Curcular Doubly Linked List)가 많이 사용된다.
🔎 헤드 노드 (Head Node)
연결 리스트에서, 맨 앞부분에 아무런 데이터가 담겨있지 않은 헤드 노드(Head Node)라는 노드를 추가하는 경우가 많다.
❕ 헤드 포인터(Head Pointer)와는 구별해야 한다. 헤드 포인터는 리스트의 첫 번째 노드를 가리키는 포인터이다.
헤드 노드를 특별히 추가하는 이유는 삽입, 삭제 알고리즘이 간편해지기 때문이다.
🔖 연결 리스트의 장점
- 배열과 달리 크기를 미리 할당할 필요가 없다.
- 데이터 삽입과 삭제가 용이하다.
- 배열과 달리 데이터들을 옮길 필요가 없이 포인터만 수정하면 된다.
- ⏱ 시간 복잡도는 $\mathbf{O(1)}$이다.
🔖 연결 리스트의 단점
- 메모리에 비연속적으로 저장되므로 임의 접근(Random Access)이 불가능하고, 특정 노드에 접근하려면 처음부터 차례대로 탐색해야 하므로 탐색 속도가 느리다.
- ⏱ 시간 복잡도는 $\mathbf{O(n)}$이다.
- 데이터뿐만 아니라 포인터도 저장해야 하므로 메모리 공간을 많이 사용한다.
🔖 연결 리스트의 사용
- 동적으로 크기를 조절해야 할 때 유용하다.
- 예를 들어, 스택이나 큐 등의 자료구조를 구현할 때 자주 사용된다.
- 데이터 삽입, 삭제가 빈번하게 일어날 때 사용하면 좋다.
📌 배열 리스트 vs 연결 리스트
| 특징 | 배열 리스트(Array List) | 연결 리스트(Linked List) |
| 메모리 배치 | 연속적인 메모리 공간에 저장 | 각 노드가 동적으로 할당되어 비연속적으로 메모리 사용 |
| 접근 속도 | O(1), 임의 접근 가능 | O(n), 순차적으로 접근해야 함 |
| 삽입 / 삭제 속도 | O(n), 중간 삽입 / 삭제 시 모든 데이터를 이동해야 함 | O(1), 중간 삽입 / 삭제 시 포인터만 수정하면 되므로 빠름 |
| 메모리 사용량 | 필요할 때 크기를 조정하지만 여유 공간이 발생함 | 각 노드가 포인터를 추가로 저장해야 함 |
참고
[자료구조] 리스트(List) - Array List, Linked List
[자료구조] 리스트(List) - Array List, Linked List
리스트 자료구조에 대한 글입니다
velog.io
연결 리스트 - IT용어위키
seb.kr
'💾 Computer Science > Algorithm' 카테고리의 다른 글
| [Algorithm] 에라토스테네스의 체(Sieve of Eratosthenes) : 소수를 구하는 고효율 알고리즘 (0) | 2024.10.15 |
|---|---|
| [Data Structure] 자료구조 - 스택(Stack) (0) | 2024.09.12 |
| [Data Structure] 자료구조 - 배열(Array) (0) | 2024.09.12 |